Introducción
La observación del comportamiento de los animales durante los experimentos es fundamental en muchas actividades científicas, como la biomecánica, genética, etología y neurociencia. Capturar las posiciones espaciales de cada uno de los miembros del animal durante el desarrollo de una actividad sin utilizar marcadores es todo un reto. Recientemente se ha presentado una herramienta informática de última generación de código abierto llamada DeepLabCutTM(DLC) basada en algoritmos de estimación de la postura, que permite al usuario entrenar una red neuronal profunda con datos etiquetados por el usuario, para rastrear con precisión las puntos de la imagen capturada previamente definidos.
La herramienta está desarrollada como un paquete de Pyhton que incluye ciertas características como la interfaz gráfica de usuario (en inglés GraphicalUser Interface, GUI) y mejoras de rendimiento y refinamiento de la red basadas en aprendizaje activo.
En esta newsletter proporcionamos una reducida guía paso a paso que permite crear un proyecto básico en DLC usando la GUI, que nos introduzca de forma fácil y amigable en el manejo de esta interesante herramienta. Además, a día de hoy, no se ha encontrado una guía de uso de esta GUI.
A continuación se desarrolla el flujo de trabajo de DLC (Fig. 1)sobre la GUI de la aplicación.
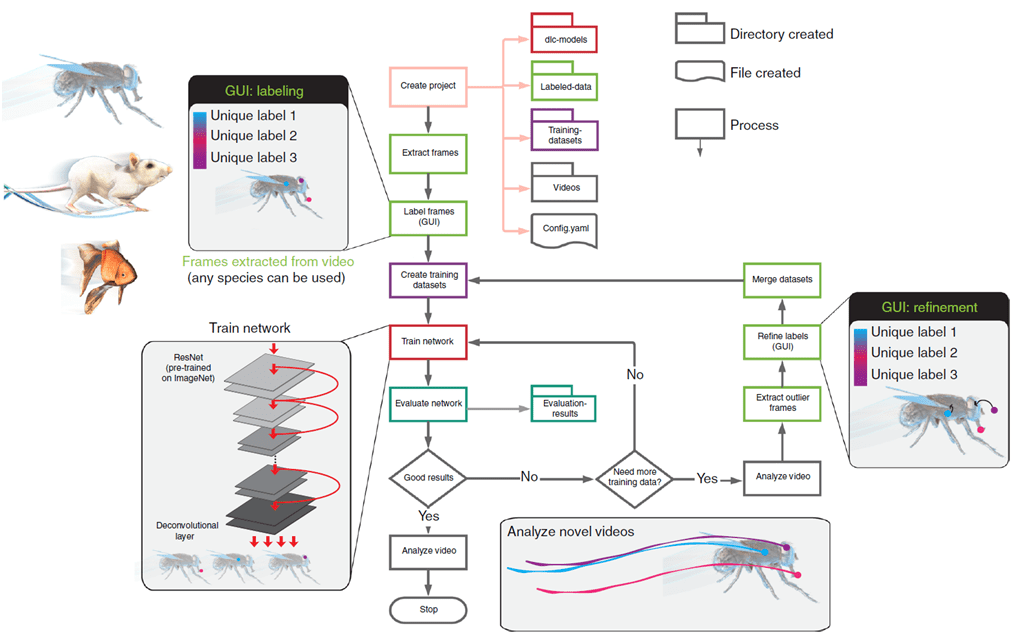
Fig. 1 Flujo de trabajo de DeepLabCut
Crear un proyecto
Una vez que hemos instalado DLC y abierto la aplicación(https://deeplabcut.github.io/DeepLabCut/docs/installation.html) se abre la pantalla de bienvenida (Fig. 2).

Fig. 2 Ventana de bienvenida de la GUI de DeepLabCut
Al hacer clic sobre el botón ‘Create New Proyect’ se abre la ventana ‘New Project’ (Fig. 3).
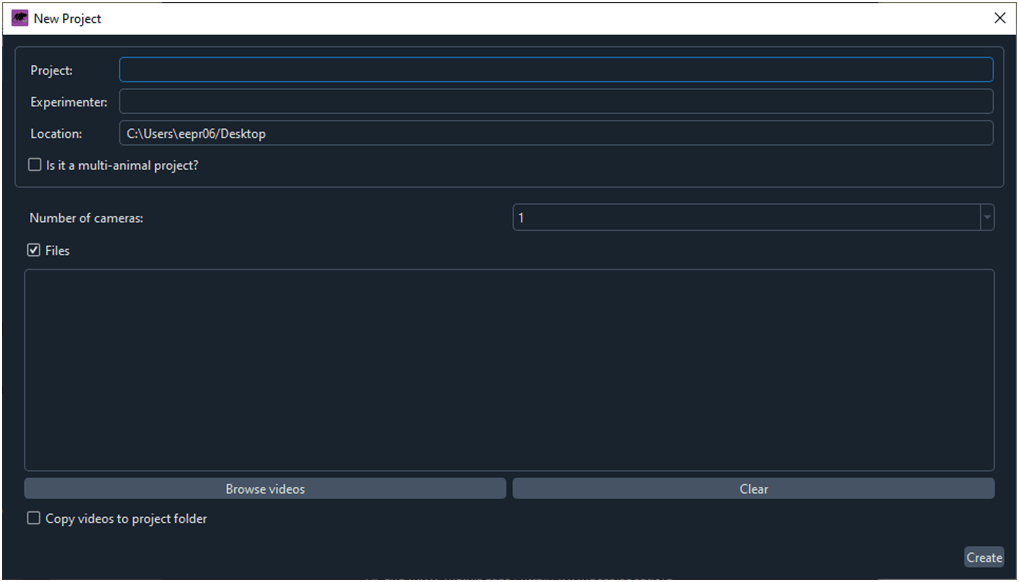
Fig. 3 Ventana para crear un proyecto nuevo.
Introducimos el nombre del proyecto, del experimentador y de la ruta donde DLC creará una carpeta con el nuevo proyecto. Con el comando ‘Browse videos’ especificamos la carpeta donde se ubican los videos que vamos a utilizar para entrenar la red neuronal.
Al hacer clic sobre ‘Create’, DLC crea la carpeta con un nombre para el proyectoque contiene las siguientes subcarpetas y archivos:
- Carpeta ‘dlc-models’: donde DLC guardará los pesos calculados para el modelo. Estos pesos son los que posteriormente DLC utilizará para predecir las variables de salida (en este caso pixel-x y pixel-y).
- Carpeta ‘Labeled-data’: esta carpeta se utilizará para gestionar los fotogramas utilizados para entrenar la red.
- Carpeta ‘Training-datasets’: en esta carpeta DLC guarda los datos que definen cómo se realizará el entrenamiento de la red neuronal.
- Carpeta ‘Videos’: aquí se guardan los videos de donde se extraen los fotogramas para el entrenamiento.
- Archivo ‘Configyaml’: es un archivo de texto editable donde el usuario especifica a DLC instrucciones acerca de la generación y aplicación del modelo.
A continuación se abre la ventana principal de trabajo de DLC que contiene una serie de pestañas que dan acceso a las diferentes fichas donde el usuario controla las acciones que se realizan con DLC (Fig. 4). En concreto, una vez creado el proyecto se abre la ventana que muestra la ficha ‘Manageproject’.
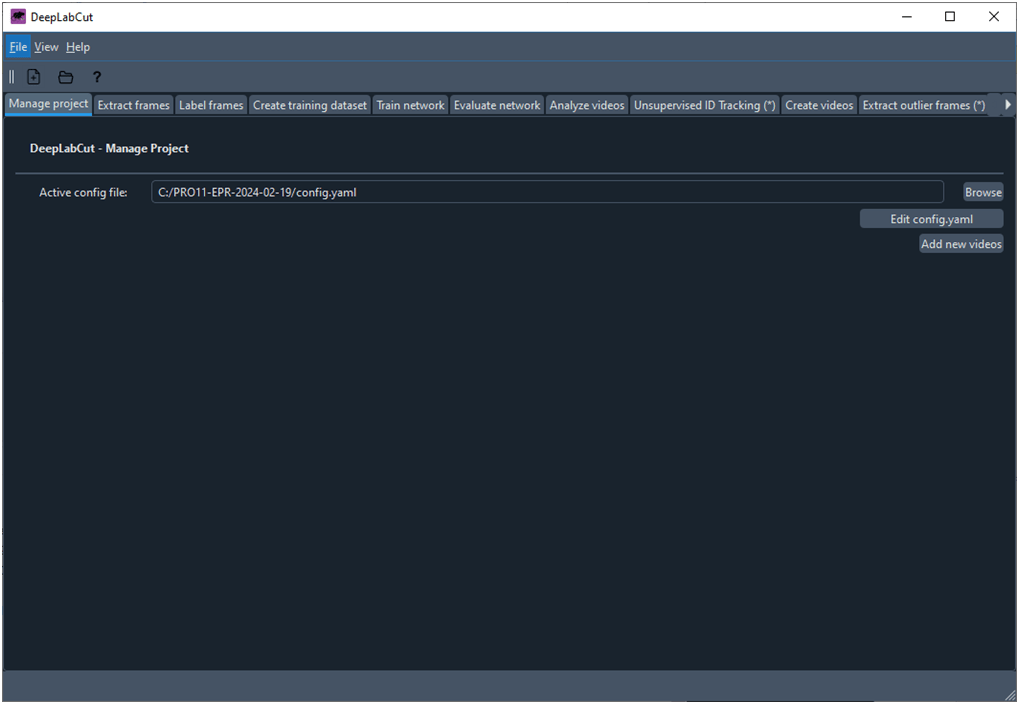
Fig. 4 Ventana principal de trabajo de DeepLabCut que muestra la ficha ‘Manage Project’
A continuación si hacemos clic sobre el botón ‘Editconfig.yaml’ tendremos acceso a cambiar ciertos parámetros para desarrollar nuestro modelo:
‘bodyparts’: introducir los nombre de las etiquetas de los puntos que queremos detectar. Un ejemplo podría ser:
- IliacCrest
- Hip
- Knee
- Ankle
- 5 Metatarsian
‘Numframes2pikc’: introducir el número de fotogramas de cada video que vamos a etiquetar manualmente para entrenar la red.Los desarrolladores de DLC recomiendan entre utilizar entre 50 y 200 fotogramas, pero para hacer una prueba de funcionamiento podríamos reducir bastante eta magnitud.
‘TrainingFraction’: en general, un estándar admitido por la comunidad es utilizar el 70 % de datos para entrenar la red y el 30 % para validar el modelo, en este caso el valor a introducir sería 0.7. Si vamos a hacer una prueba con un reducido número de fotogramas sería mejor aumentar este parámetro, 0.95 es lo que DLC propone por defecto; esto lo deberíamos tener en cuenta a la hora de evaluar el modelo.
Obtener Fotogramas de Entrenamiento
La ficha ‘Extracframes’ contiene las instrucciones para obtener los fotogramas que DLC necesita para entrenar la red y para validar el modelo (Fig. 5). Como veremos, previamente estos fotogramas deben ser etiquetados.

Fig. 5 Ficha para obtener los fotogramas de entrenamiento.
DLC permite seleccionar entre diferentes métodos para la obtención de los fotogramas. Se pueden obtener de manera manual o automática. Si el movimiento que estamos estudiando varía a lo largo del video sin ninguna dependencia temporal el algoritmo ‘uniform’ sería la opción adecuada, si el movimiento se concentra en una parte del video, por ejemplo el estudio de un agarre, la opción ‘kmeans’ sería más adecuada.
Para una prueba estándar se pueden dejar los parámetros de la Fig. 5, que DLC propone por defecto.Con la opción ‘kmeans’ nos aseguramos de que los fotogramas no van a ser parecidos, lo cual es muy conveniente para el entrenamiento.
Al hacer clic sobre ‘ExtractFrames’,DLC crea una subcarpeta por cada video de entrenamiento en la carpeta ‘Labeled-data’. Cada subcarpeta contendrá los fotogramas del video seleccionados para el entrenamiento.
Etiquetar fotogramas
Haciendo clic sobre ‘Labelframes’ (Fig. 6) DLC nos pregunta por la subcarpeta ubicada en ‘Labeled-data’ donde se encuentran los fotogramas que deseamos etiquetar. Realizado la anterior acción se abre la GUI de etiquetado de fotogramas (Fig. 7).

Fig. 6 Ficha que da acceso a la GUI de etiquetado

Fig. 7 GUI de etiquetado de fotogramas
En la parte inferior derechade la GUI de etiquetado aparecen las etiquetas (‘keypoints’ o ‘bodyparts’) que introdujimos en el archivo ‘config.yaml’. Utilizar los controles en la parte superior izquierda para etiquetar: la diana para ubicar una etiqueta y la ‘x’ para eliminar una etiqueta. Con la barra inferior nos movemos entre los diferentes fotogramas. Finalmente, antes de cerrar la ventana es necesario salvar los datos.
Crear conjunto de datos de entrenamiento
Para entrenar la red neuronal es necesario crear un conjunto de datos de entrenamiento. De todos los fotogramas etiquetados DLC toma un grupo para entrenar la red y otro grupo para validar el modelo, según ‘TrainingFraction’ en ‘config.yaml’. Podemos dejar la ficha ‘Create training dataset’ con la configuración por defecto (Fig. 8). El campo ‘Shuffle’ es para diferenciar entre modelos y poder compararlos. Con el parámetro ‘imgaug’ se expande artificialmente el conjunto de entrenamiento aplicando varias transformaciones a las imágenes (por ejemplo, rotación o cambio de escala) para generar modelos más robustos y precisos.
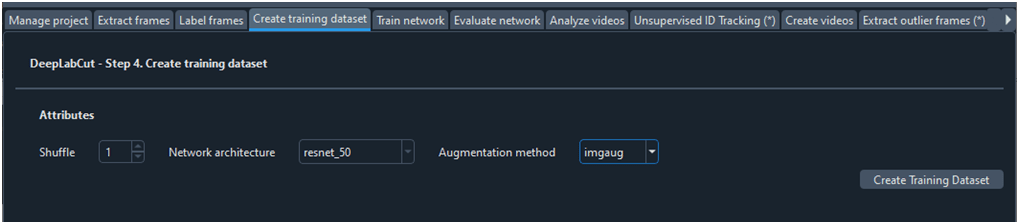
Fig. 8 Ficha para crear un conjunto de datos de entrenamiento
Entrenar la red neuronal
Para entrenar la red neuronal utilizamos la ficha ‘Train network’ (Fig. 9). Al hace clic sobre el botón ‘Train Network’ comienza un proceso de cálculo paramétrico iterativo y continuo basado en árboles de decisión durante el cual se van actualizando los pesos de los parámetros con los que luego se realizarán la predicciones. Se puede visualizar la pérdida del modelo cada ciertas iteraciones (‘Displayiterations’), se puede guardar el modelo cada ciertas iteraciones (‘Saveiterations’) y se puede configurar el número máximo de modelos que queremos guardar (‘number of senashots to keep’). También se debe configurar el máximo número de iteraciones que queremos realizar para entrenar la red (‘Maximumiterations’).
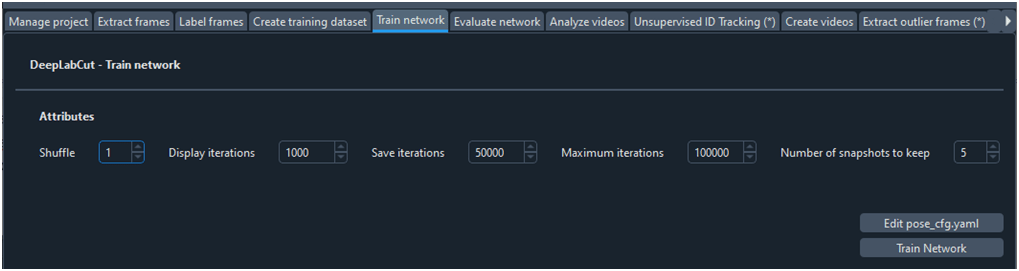
Fig. 9 Ficha para entrenar una red neuronal
El proceso de entrenar la red puede demorarse varias horas, multiplicándose por 10 en caso de que no dispongamos de una tarjeta gráfica dedicada.
Evaluar la red neuronal
Es importante evaluar la bondad de la red entrenada. En este paso DLC aplica el modelo a todos los fotogramas, tanto a los de entrenamiento como a los de validación, y calcula el error y la probabilidad para ambos grupos.Al hacer clic sobre el botón ‘Evaluate Network’ de la ficha ‘Evaluatenetworw’ (Fig. 10) DLC crea la carpeta ‘evaluation-results’ dentro de la carpeta del proyecto. Esta carpeta contiene un archivo ‘.csv’ con los resultados de la evaluación (Fig. 11), si se selecciona la opción ‘Plotpredictions’ se genera una carpeta con los fotogramas de entrenamiento y de test en los que se muestran las etiquetas de entrenamiento y las estimadas por el modelo (Fig. 12).
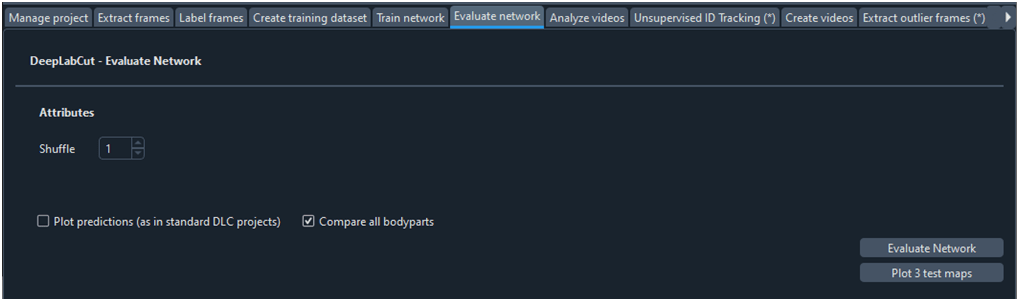
Fig. 10 Ficha para evaluar la red neuronal

Fig. 11 Hoja de resultados de la evaluación de diferentes modelos
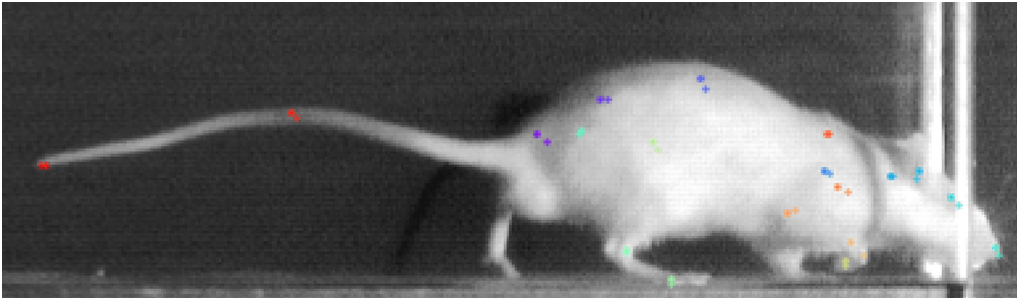
Fig. 12 Ejemplo de fotograma mostrando las etiquetas de entrenamientos y las estimadas por el modelo
Analizar videos
Para obtener las coordenadas xyde un vídeo o conjunto de vídeos hacemos uso de la ficha ‘Analyze videos’ (Fig. 13). Con esta función DCL aplica el modelo a cada fotograma del video en cuestión, calcula las coordenadas x e y en píxeles y la probabilidad de que el pixel estimado se encuentre donde se ha calculado. Al hacer clic sobre el botón ‘Analize Videos’ DLC crea en la carpeta donde se encuentra el video a analizar, además de otros archivos, un archivo ‘csv’ con los valores anteriormente comentados para cada fotograma y para cada etiqueta (o ‘bodyparts’ en config.yaml) (Fig. 14). Marcar la opción ‘Filterpredictions’ para obtener un archivo ‘csv’con los datos filtrados. La opción ‘Plottrajectories’ proporciona cuatro gráficos muy útiles para visualizar el análisis del video (Fig. 15, Fig. 16, Fig. 17 y Fig. 18).
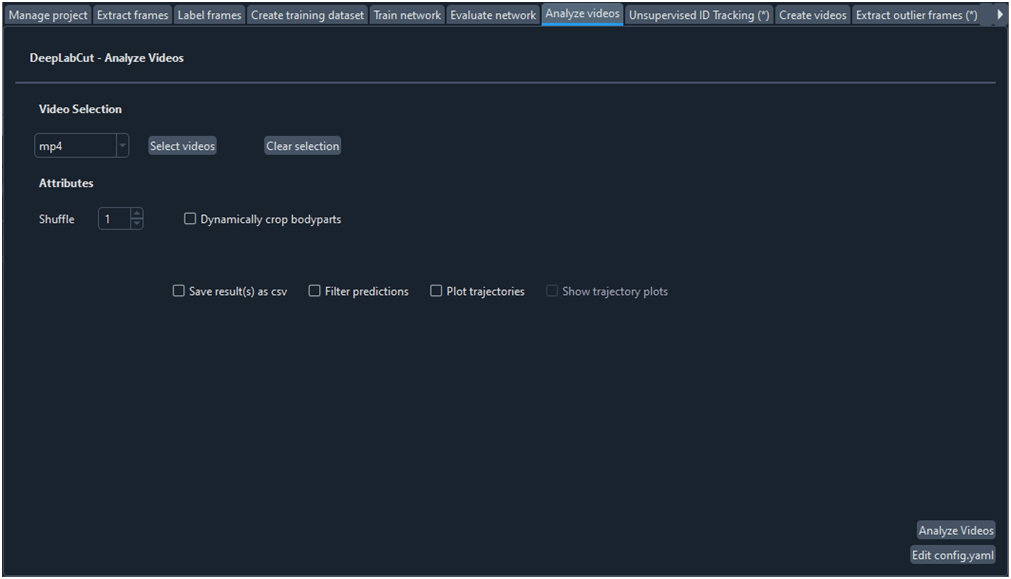
Fig. 13 Ficha para analizar un vídeo
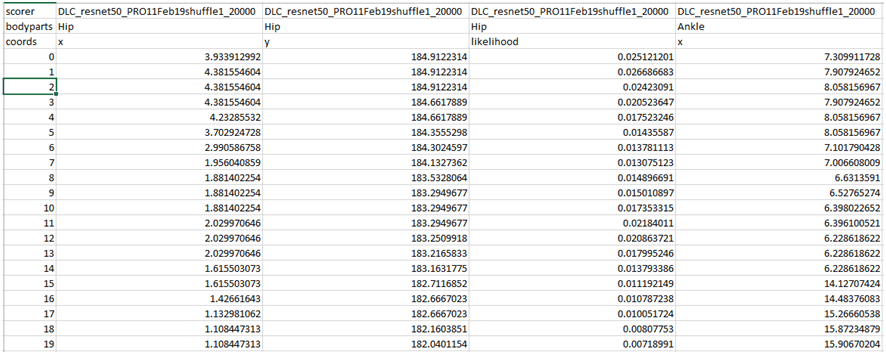
Fig. 14 Archivo ‘csv’ con las coordenadas x-pixel e y-pixel y la probabilidad para cada fotograma y para cada etiqueta
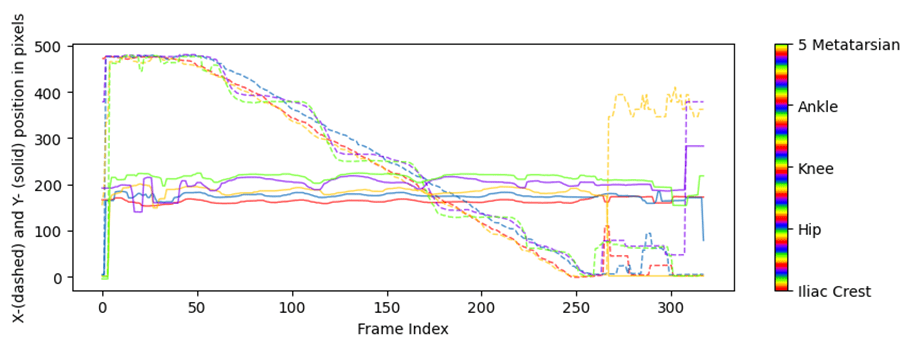
Fig. 15 Coordenadas ‘x-pixel’ e ‘y-pixel’ frente al tiempo
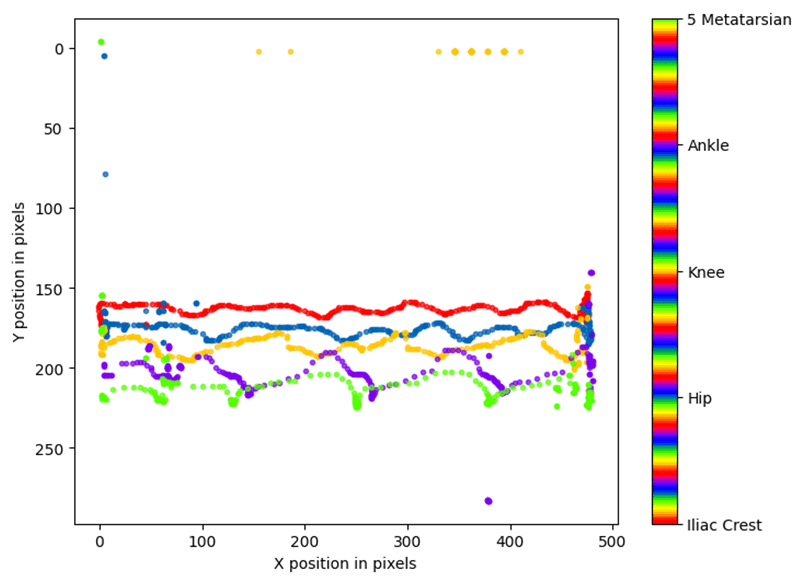
Fig. 16 Posiciones de las ‘bodyparts’

Fig. 17 Histograma de diferencias entre posiciones consecutivas de ‘bodyparts
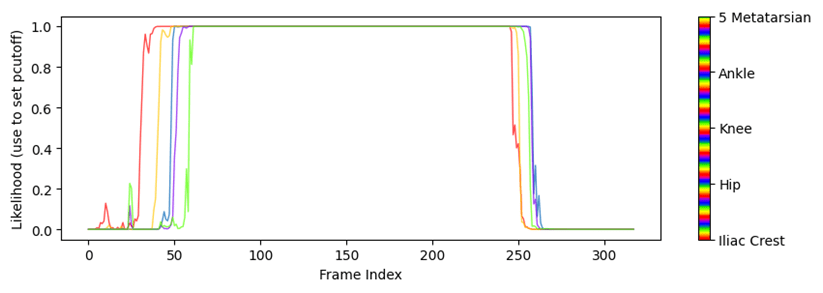
Fig. 18 Probabilidad de las ‘bodyparts’ frente al tiempo
Referencias
Nath, T., Mathis, A., Chen, A.C. et al. Using DeepLabCut for 3D markerless pose estimation across species and behaviors. Nat Protoc 14, 2152–2176 (2019).
DeepLabCut: a software package for animal pose estimation. http://www.mackenziemathislab.org/deeplabcut
AUTORES
Enrique Pérez Rizo, M.E., PhD.
Ingeniero de Biomecánica
Unidad de Ingeniería y Evaluación Motora
Hospital Nacional de Parapléjicos
Toledo, España
Juan Manuel Berruezo Conejo
Estudiante de Ingeniería Electrónica Industrial y Automática
Grupo AppliedIntelligentSystems. Escuela de Ingeniería Industrial y Aeroespacial de Toledo
Universidad de Castilla la Mancha
Toledo, España
Para más información puedes contactarnos en: enriquep@sescam.jccm.es
Si quieres conocer más sobre nosotros: Servicios de apoyo a la investigación HNP
Síguenos en:
www.linkedin.com/in/servicios-de-apoyo-a-la-investigación-sais-hnp
