Introducción
Como ya se mostró en newsletters anteriores el seguimiento de marcadores en registros de video de alta velocidad para el análisis cinemático de la locomoción en roedores es una labor tediosa que consume una gran cantidad de tiempo del operador. Por ello, en la Unidad de Ingeniería y Evaluación Motora (UIEM) actualmente se está implementando un algoritmo basado en inteligencia artificial que pretende realizar este seguimiento de manera automática. Además, con el software KineRAT, también desarrollado en la UIEM, se ha conseguido automatizar completamente todo el postprocesado de las variables cinemáticas de esta prueba, reduciéndolo a un clic de ratón. Cuando consigamos tener en marcha el seguimiento automático de marcadores, junto con el KineRAT dispondremos de una prueba de bajo coste con capacidad de aportar información fundamental del estado neurológico de nuestros animales de experimentación.
En esta newsletter se presenta una de las bibliotecas de aprendizaje automático ampliamente utilizada en Python: Scikit-Learn. Esto nos permitirá hacer una introducción práctica al Machine Learning y mostrar un ejemplo de uso.
Machine learning
El Machine Learning o Aprendizaje Automático es una rama de la inteligencia artificial que se centra en el diseño y desarrollo de algoritmos y modelos estadísticos que permiten a las computadoras aprender y mejorar su rendimiento en una tarea específica, sin ser explícitamente programadas para ello.
En lugar de utilizar reglas explícitas, el Machine Learning utiliza datos y algoritmos para identificar patrones y relaciones en los datos, lo que permite a la computadora realizar predicciones, clasificaciones o toma de decisiones basadas en esos patrones. A medida que se alimenta la computadora con más datos, el algoritmo puede ajustarse y mejorar su rendimiento en la tarea.
El Machine Learning tiene una amplia variedad de aplicaciones prácticas, incluyendo la detección de fraudes en las transacciones financieras, el análisis de imágenes médicas, la recomendación de productos en línea o la conducción autónoma de vehículos.
Aunque el Machine Learning es una técnica poderosa y prometedora en la resolución de problemas complejos, también tiene algunas limitaciones y desafíos que pueden afectar su aplicación en diferentes contextos. Algunas de las limitaciones comunes del Machine Learning son:
- Dependencia de los datos. El rendimiento de los modelos de Machine Learning depende en gran medida de la calidad y cantidad de los datos utilizados para entrenarlos. Si los datos son sesgados o incompletos, el modelo también lo será.
- Sobresimplificación.Los modelos de Machine Learning pueden simplificar en exceso un problema, lo que puede llevar a la omisión de detalles importantes y la subestimación de la complejidad.
- Interpretabilidad. A menudo, los modelos de Machine Learning son difíciles de interpretar, lo que puede hacer que sea difícil para los expertos entender cómo funcionan o cómo se toman las decisiones.
- Costo computacional. Los modelos de Machine Learning pueden requerir una gran cantidad de recursos computacionales para entrenar y aplicar, lo que puede ser costoso en términos de tiempo y recursos.
- Sesgo algorítmico. Los algoritmos de Machine Learning pueden perpetuar sesgos existentes en los datos de entrenamiento, lo que puede tener consecuencias negativas en la toma de decisiones y la equidad.
Es importante tener en cuenta estas limitaciones al utilizar técnicas de Machine Learning y ser consciente de cómo pueden afectar la precisión y la confiabilidad de los resultados.
Qué es Scikit-Learn
En primer lugar, hay que indicar que Python es un lenguaje de programación interpretado y de alto nivel, caracterizado por su simplicidad y legibilidad. Una de sus principales características es su sintaxis clara y concisa, que facilita la lectura y comprensión del código, lo que ayuda a los programadores a escribir programas más legibles y menos propensos a errores. Es un lenguaje orientado a objetos ymultipropósito, lo que significa que se puede utilizar en una amplia gama de aplicaciones.
Scikit-Learn es una biblioteca de aprendizaje automático extremadamente popular y ampliamente utilizada en la comunidad de Python. Ofrece una amplia gama de algoritmos y herramientas que facilitan la implementación y la aplicación de técnicas de aprendizaje automático en diversos problemas.
Una de las ventajas destacadas de Scikit-Learn es su facilidad de uso y su enfoque en la simplicidad. La biblioteca proporciona una interfaz coherente y bien documentada, lo que facilita a los desarrolladores el uso de los algoritmos sin la necesidad de entender los detalles de su implementación subyacente.
Otra fortaleza de Scikit-Learn es su integración con otras bibliotecas populares de Python. Por ejemplo, se integra de manera excelente con NumPy y SciPy, lo que permite un procesamiento eficiente de datos y cálculos numéricos. Además, se puede combinar fácilmente con Pandas para manipular y transformar datos, y con Matplotlib para visualizar los resultados.
Además de su facilidad de uso, Scikit-Learn también destaca por su rendimiento y eficiencia. Los algoritmos están implementados de manera optimizada, lo que permite trabajar con conjuntos de datos grandes y manejar la complejidad de los problemas de aprendizaje automático.
Otra característica importante de Scikit-Learn es su enfoque en la validación y evaluación de modelos. La biblioteca proporciona herramientas para realizar validación cruzada, ajustar los hiperparámetros y evaluar el rendimiento de los modelos utilizando diversas métricas. Esto es fundamental para tomar decisiones informadas sobre la elección del modelo y la optimización de sus parámetros.
En resumen, Scikit-Learn es una biblioteca sólida y confiable para el aprendizaje automático en Python. Su facilidad de uso, amplia gama de algoritmos y herramientas, rendimiento eficiente y enfoque en la evaluación de modelos la convierten en una elección popular para aquellos que desean aplicar técnicas de aprendizaje automático en sus proyectos.
Tipos de aprendizaje
El Aprendizaje Supervisado y el Aprendizaje No Supervisado son dos enfoques distintos dentro del Machine Learning que se utilizan para entrenar modelos y resolver diferentes tipos de problemas (Figura 1).
El Aprendizaje Supervisado se basa en la utilización de datos etiquetados para entrenar un modelo que pueda realizar predicciones precisas sobre datos no vistos. En este enfoque, el modelo se entrena utilizando un conjunto de datos de entrada y una etiqueta asociada a cada dato de salida, lo que permite al modelo aprender a predecir correctamente la etiqueta de nuevos datos. Por ejemplo, se puede utilizar el Aprendizaje Supervisado para predecir el precio de una casa en función de su tamaño, ubicación y características similares.
Por otro lado, el Aprendizaje No Supervisado se basa en la utilización de datos no etiquetados para identificar patrones o estructuras ocultas en los datos. En este enfoque, el modelo se entrena sin la ayuda de etiquetas explícitas, lo que permite que el modelo aprenda por sí solo a identificar patrones y relaciones en los datos. Por ejemplo, se puede utilizar el Aprendizaje No Supervisado para agrupar automáticamente a los clientes en segmentos de mercado similares en función de sus hábitos de compra.
Dentro del aprendizaje supervisado se puede dar un problema de regresión, si los valores asociados son continuos, o un problema de clasificación, si lo valores asociados son categorías. En el caso de clasificación, si se dan dos clases se denomina clasificación binaria y si se dan más de dos clases se denomina clasificación multiclase.
Scikit-Learn dispone de algoritmos de aprendizaje supervisado, tanto de clasificación binaria como multiclase, y no supervisado, destacando en este último caso los métodos de clustering o agrupamiento.
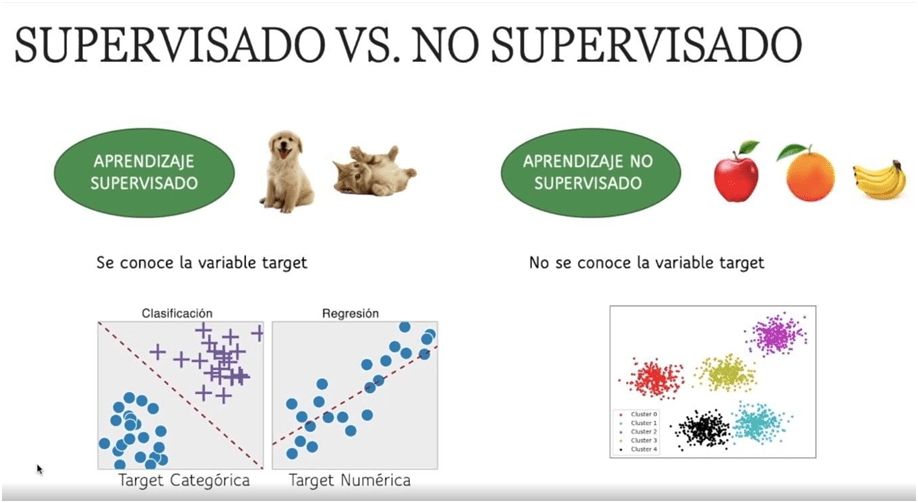
Figura 1. Diferencias entre los dos tipos de aprendizaje automático (imagen descargada de https://escuelafullstack.com/).
Datasets de Scikit-Learn
Dentro de Scikit-Learn están disponibles una gran cantidad de conjuntos de datos, cada uno para un problema diferente, con objeto de que el usuario diseñe y pruebe sus algoritmos de aprendizaje. Por ejemplo, el conjunto de datos iris, el cual es un datasetcreado por Ronald Fisher en el año 1936, en el que se encuentran contenidas 50 muestras de cada una de las especies de la flor iris (iris setosa, iris virginica, iris versicolor)(Figura 2). Se midieron 4 rasgos de cada muestra: el largo y el ancho de los sépalos y pétalos, en centímetros. Este conjunto de datos es muy adecuadocomo ejemplo de uso para problemas de clasificación.

Figura 2. Pétalo y Sépalo de una flor iris (imagen descargada de https://aprendeia.com).
Otro ejemplo de dataset es el denominado digits que se compone de 64 imágenes de 8×8 píxeles de dígitos escritos a mano (Figura 3).

Figura 3. Cuarenta primeras imágenes del datasetdigits de la librería Scikit-Learn (imagen descargada de https://scikit-learn.org).
Algoritmos de Scikit_Learn
A menudo, la parte más difícil en cuanto a resolver un problema de aprendizaje automático puede ser encontrar el estimador adecuado para el trabajo.Diferentes estimadores son más adecuados para diferentes tipos de datos y para diferentes problemas.
La Figura 4 muestra el diagrama de flujo que brinda Scikit-Learna los usuarios como guía aproximada sobre cómo abordar los problemas con respecto a qué estimadores probar en sus datos.Se puede comprobar que con menos de 50 datos no se puede hacer nada. Si el problema es de clasificación categórica y los datos están etiquetados se podrían aplicar algoritmos de clasificación, pero si no están etiquetados la opción es aplicar algoritmos de clustering. Si el problema es predecir un valor o cantidad habría que aplicar, dependiendo del número de muestras, algún algoritmo de regresión. Si no se pretende predecir un valor y lo que se quiere es reducir las variables se podrían aplicar algoritmos de reducción de la dimensionalidad.

Figura 4. Chuleta sobre las estrategias a seguirque ofreceScikit-Learn a la hora de elegir un algoritmo si se pretende resolver un problema determinado (imagen descargada de https://scikit-learn.org).
Como se aplica un clasificador o un estimador en Scikit-Learn
Uno de los principales usos que se puede hacer del Machine Learning es el desarrollo de clasificadores. Para poder entrenar un clasificador es necesario recopilar un conjunto de datos que contenga el mayor número de casos distintos que se pudieran dar. Cada caso estará representado por un conjunto de muestras diferentes que lo describen. De cada muestra se extrae la información de los rasgos que pudieran definir mejor la población,por ejemplo, si se pretende construir un clasificador de imágenes, se podrían utilizar los valores de cada pixel de la imagen o utilizar rasgos como dimensiones, formas, etc. calculados a partir de estas, y así reducir notablemente el tamaño de la información. A su vez, un especialista clasifica manualmente el conjunto de datos, asignando una clase a cada muestra mediante una etiqueta. Para evitar sesgos, es importante que tanto los casos como las muestras estén balanceados.
Determinado el conjunto de datos estos se dividen en un grupo de entrenamiento y en un grupo de validación. Una aproximación simple podría ser escoger de forma aleatoria 2/3 de los datos para el entrenamiento y el resto para la validación.
Una vez elegido el algoritmo clf que se va a utilizar se construye el clasificador, es decir, se entrena el algoritmo usando la función fit como se muestra en la ecuación 1. El proceso de entrenamiento implica alimentar al algoritmo los ejemplos de entrada Xy las salidas esperadas correspondientes, es decir su clase o etiqueta y. El algoritmo utiliza estos datos para ajustar sus parámetros internos, lo que le permite aprender y mejorar su capacidad para generalizar a nuevas situaciones.
Ecuación 1
Completado el proceso de entrenamiento, el algoritmo está listo para hacer predicciones (a) o tomar decisiones sobre nuevos datos (t) que no se utilizaron durante el entrenamiento mediante el uso de la función predict como se muestra en la ecuación 2.
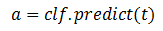
Ecuación 2
A partir de aquí, introduciendo los datos de validación al clasificador se puede calcular la bondad del clasificador y si esta se ajusta a nuestras demandas consecutivamente se puede estimar la clase de cualquier espécimen o situación de la población introduciendo al clasificador los datos de entrada del mismo.
A continuación, mediante un sencillo ejemplo, se va a demostrar cómo de aplica un clasificador.
Ejemplo de redes neuronales para dataset iris
El objetivo es construir un clasificador que a partir de las medidas de ancho y largo de los pétalos y sépalos de una flor de iris cualquiera determine si esta es de la especie setosa, virgínica o versicolor.
Se importan las librerías que se van a necesitar.
Para calcular el clasificador se va a utilizar un algoritmo de redes neuronales llamado perceptron multicapa de tipo supervisado. Se carga el algoritmo en la memoria.
fromsklearn.neural_networkimportMLPClassifier
Se carga en la memoria el dataset iris
fromsklearn.datasetsimportload_iris
Se carga la librería numpy de cálculo y manejo de arrays.
importnumpyasnp
Se preparan los datos
Se crea la variable iris con el dataset.
iris=load_iris()
A partir de la variable iris se crean las variables de entrada del clasificador: X_train es un array con las dimensiones de cada una de las flores que componen la muestra, y_train es un arraycon las etiquetas que corresponden a cada una de las flores.
X_train=iris.data
y_train=iris.target
Se visualizan los datos de las etiquetas utilizadas en el dataset.
print(iris.target_names)
['setosa' 'versicolor' 'virginica']
En el siguiente código se realiza un preprocesamiento de los datos. En el caso de las redes neuronales, estas no se comportan adecuadamente cuando no se controla la escala de los datos. Se normalizan los datos de entrada.
fromsklearn.preprocessingimportStandardScaler
scaler=StandardScaler()
scaler.fit(X_train)
X_train=scaler.transform(X_train)
Se adecuan las etiquetas situándolas a continuación unas de otras.
y_train=y_train.ravel()
Se crea y se aplica el clasificador
Se crea el clasificador a partir de un perceptrón multicapa con tres capas ocultas de tamaño 10 y número máximo de iteraciones igual a 1000.
clf=MLPClassifier(hidden_layer_sizes=(10,10,10),max_iter=1000)
Se entrena el clasificador con los datos de entrada.
clf.fit(X_train,y_train)
MLPClassifier(hidden_layer_sizes=(10, 10, 10), max_iter=1000)
La función predict aplica el clasificador a cualquier conjunto de datos dimensionales de una flor y aporta la etiqueta correspondiente según el clasificador generado.La función reshape adecúa las dimensiones de los datos de entrada.
etiqueta = clf.predict(X_train[12].reshape(1,-1)
print('Etiqueta clasificador: ',etiqueta),
'Etiqueta de la flor: ',iris.target[12])
Salida:
Etiqueta clasificador: [0] Etiqueta de la flor: 0
Se realiza una preevaluación con los mismos datos de entrenamiento. Esta evaluación ejemplifica el uso de la función predict, carece de ningún valor. No se deben utilizar los valores de entrenamiento para la evaluación.
tr_exactitud=np.mean(clf.predict(X_train)==y_train)
print("Exactitud:",tr_exactitud)
Salida:
Exactitud: 0.98
Se evalúa el clasificador
El código siguiente divide el dataset en cinco grupos. Toma un grupo para entrenar y utiliza los cuatro restantes para la validar el clasificador. Esto se realiza iterativamente para los cinco grupos de datos. De esta manera se podría evaluar cuáles el conjunto de datos que predice mejor los valores de entrada.
fromsklearn.model_selectionimportKFold
X=X_train
kf=KFold(n_splits=5,shuffle=True)
fortr,tstinkf.split(X):
X_train=X[tr,:]
y_train=iris.target[tr]
X_test=X[tst,:]
y_test=iris.target[tst]
clf.fit(X_train,y_train)
tr_exactitud=np.mean(clf.predict(X_test)==y_test)
print("Exactitud:",tr_exactitud)
Salida:
Exactitud: 0.9333333333333333
Exactitud: 0.9666666666666667
Exactitud: 0.9666666666666667
Exactitud: 0.9666666666666667
Exactitud: 0.9333333333333333
Referencias
Generación de algunas partes del texto: Modelo de lenguaje ChatGPT AI de OpenAI, ¿qué es machine learning? limitaciones de machine learning, ¿Qué es Scikit-Learn?, 09 de mayo de 2023.
Algunas ideas extraídas de: Apuntes de Miguel García Silvente del curso Python avanzado para Tratamiento de Datos e Inteligencia Artificial (V ed.) del Dentro Mediterráneo de la Universidad de Granada.
AUTORES
Enrique Pérez Rizo, M.E., PhD.
Ingeniero de Biomecánica.
Unidad de Ingeniería y Evaluación Motora
Unidad de Investigación – Hospital Nacional de Parapléjicos.
Toledo, España.
Arturo Fernández Mora.
Estudiante de Ingeniería Electrónica Industrial y Automática.
Grupo AppliedIntelligentSystems. Escuela de Ingeniería Industrial y Aeroespacial de Toledo.
Universidad de Castilla la Mancha.
Toledo, España.
Para más información puedes contactarnos en: enriquep@sescam.jccm.es
Si quieres conocer más sobre nosotros: Servicios de apoyo a la investigación HNP
Síguenos en:
www.linkedin.com/in/servicios-de-apoyo-a-la-investigación-sais-hnp
